
一、背景说明
随着 Web 技术的快速发展,目标站点(如 TikTok、Instagram、各大电商平台、内容社区)普遍具备以下特征:- 动态内容渲染:页面内容高度依赖 JavaScript 执行后生成
- 异步数据加载:关键数据通过 XHR/Fetch 请求动态获取
- 复杂反爬机制:包括但不限于浏览器指纹检测、行为分析、验证码、请求频率限制
- API保护策略:接口参数加密、令牌验证、签名校验
- 响应式设计:针对不同设备返回差异化内容
平台的核心价值:为采集框架提供稳定的基础设施,包括:用户无需自行搭建和维护这些复杂系统,可专注于业务逻辑(页面解析与数据提取)。
- 纯净、动态的代理IP池 - 自动处理IP轮换与地域切换
- 真实的浏览器指纹环境 - 模拟不同设备、操作系统,对抗高级反爬
- 统一的并发与队列管理 - 优化资源使用,避免目标站点过载
- 任务调度、监控与错误重试 - 保障采集任务的长期稳定运行
二、为什么不推荐使用原生 Python 请求
❌ 原生 Python 的典型写法
存在的问题
结论:
原生 Python 更适合 调用稳定 API,而不适合 采集现代网页页面。
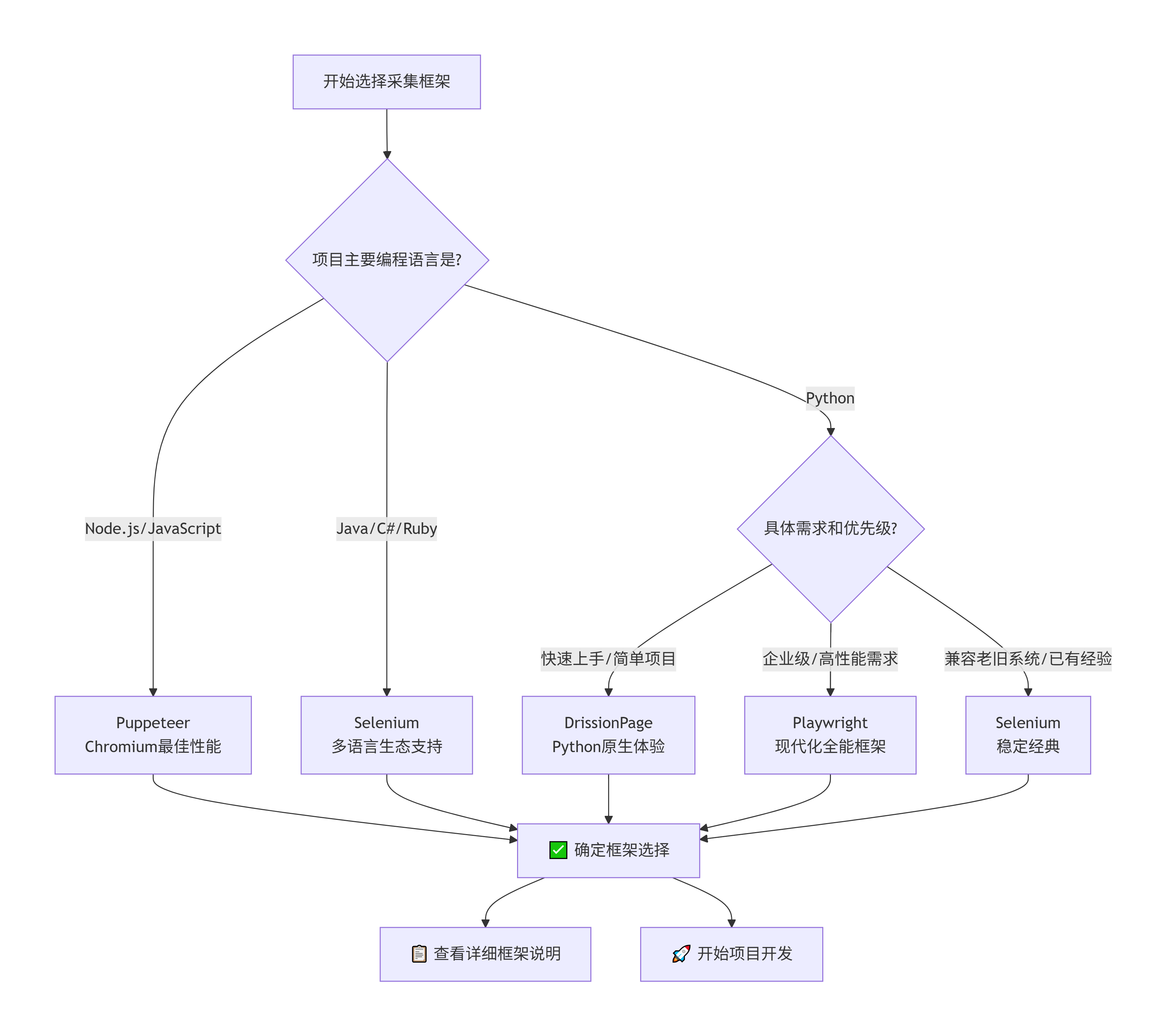
三、采集框架对比及说明
✅ 对比表
1️⃣ DrissionPage
DrissionPage 是一个 Python 封装库,整合了 Selenium + requests,支持无头浏览器和静态请求结合的模式。优点:
- Python 原生,API 高层封装,操作网页像操作 DOM 一样简单。
- 可以同时使用 Selenium 驱动浏览器渲染 JS 和 requests 直接抓取静态数据,减少浏览器开销。
- 内置一些常用功能:自动等待、登录会话保持、截图、JS 执行等。
- 对初学者友好,上手快。
- 基于 Selenium,底层性能和浏览器兼容性取决于 Selenium。
- 只能在 Python 中使用。
- 社区和生态不如 Playwright、Selenium 大。
- 高级功能(比如拦截网络请求、模拟复杂手势)不如 Playwright 灵活。
- Python 项目,需要同时抓静态和动态网页。
- 项目对高性能要求不高,但需要快速实现。
2️⃣ Playwright
Microsoft 开发的现代浏览器自动化库,支持多语言(Python/Node.js/Java/.NET)。优点:
- 支持多浏览器(Chromium, Firefox, WebKit)。
- 性能优异,底层基于浏览器 DevTools 协议,比 Selenium 更稳定。
- API 高级:自动等待元素、网络拦截、模拟设备、可控上下文。
- 支持无头和有头浏览器,支持多标签页、多浏览器上下文。
- 支持多语言,跨平台。
- 相对 Puppeteer,Python 版本略慢(Node.js 最优)。
- 学习成本稍高,功能丰富但需要理解上下文概念。
- 生态比 Selenium 小,但正在快速增长。
- 高性能爬虫、自动化测试、跨浏览器测试。
- 需要精细控制浏览器行为(拦截请求、模拟手机端、截图、PDF 等)。
3️⃣ Selenium
历史最久的浏览器自动化工具,几乎支持所有主流浏览器。优点:
- 历史悠久,社区庞大,几乎可以找到所有问题的解决方案。
- 多语言支持(Java/Python/C#/Ruby/JS)。
- 兼容性好,支持 Chrome/Edge/Firefox/Safari 等。
- 可以直接操作真实浏览器,适合测试和复杂场景。
- 性能相对低,启动浏览器慢。
- 对 JS 动态渲染页面处理不够灵活,常需要显式等待。
- API 相对低级,需要自己封装等待、错误处理。
- 网络请求控制较困难,需要额外代理或中间件。
- 自动化测试(Web 测试)。
- 需要兼容各种老旧浏览器的场景。
- Python/Java 等多语言项目中稳定性优先。
4️⃣ Puppeteer
Google 官方推出,专门针对 Chromium 的 Node.js 库。优点:
- 专注 Chromium,性能和稳定性非常高。
- API 设计现代化,操作网页像操作浏览器对象一样自然。
- 强大的功能:截图、PDF、拦截请求、模拟设备、模拟用户输入。
- Node.js 原生,适合 JS/TS 项目。
- 只支持 Chromium 系列(Chrome/Edge),跨浏览器能力弱。
- Python 需要通过 pyppeteer 或者其他封装库,但更新慢。
- 对非 Chromium 浏览器支持不理想。
- Node.js 项目爬虫、自动化测试。
- Chromium 专用的网页抓取、截图、PDF 导出。
- JS 项目中快速自动化浏览器操作。
🗺️ 选择决策流程图
四、官方推荐架构
平台脚本推荐采用以下职责划分: 复制代码职责说明
五、结论
当目标站点是”现代Web应用”而非”传统网页”时,使用真实浏览器环境不是优化选择,而是基本前提。因此,在平台脚本中,官方推荐使用DrissionPage,Playwright,Selenium, Puppeteer作为标准页面采集框架。